| |
|
| 9.12. Verallgemeinerte
Differenzierbarkeit |
Methoden der linearen Algebra mit Begriffen aus der Analysis zu kombinieren,
führt oft zu reichhaltigen, neuen Theorien. In diesem Abschnitt soll eine
solche Kombination am Beispiel der Differenzierbarkeit vorgestellt werden. Die
resultierende neue Theorie, die Distributionentheorie, wurde gegen Ende
der 1940er Jahre von Laurent
Schwartz entwickelt.
Wir beschränken uns auf einige grundlegende Aspekte
der Distributionentheorie, die bereits mit sparsamen Bedingungen entwickelt
werden können. Die folgenden drei Punkte sind daher zu beachten:
- Unsere Distributionen müssen nur eine algebraische Bedingung, die
Linearität, erfüllen. Die sonst übliche Forderung nach einem
speziellen Konvergenzverhalten stellen wir nicht.
- Mit dem Stammfunktionen-Integral steht uns nur ein eingeschränkter
Integralbegriff zur Verfügung. Das eine oder andere Beispiel wird daher
nicht in der größtmöglichen Allgemeinheit dargestellt werden können.
- Nach wie vor betrachten wir nur reelle Funktionen in einer
Veränderlichen.
Wir beginnen mit der Bereitstellung der für die Theorie notwendigen Grund-
oder Testfunktionen. Dabei sei noch einmal an den Begriff "Träger
einer Funktion" erinnert: .
| Definition: Die Funktionen aus
nennen wir Testfunktionen.
|
Beachte:
Eine -Funktion ist also nur dann eine Testfunktion, wenn sie außerhalb eines geschlossenen
Intervalls nur den Wert 0 annimmt. Unter den gewöhnlichen -Funktionen findet man ein solches Verhalten eher nicht. Es müssen also Beispiele
konstruiert werden.
| Dabei spielt die Funktion
gegeben durch
|
|
eine große Rolle. f ist eine -Funktion,
denn wir zeigen für alle :
und mit geeigneten Konstanten
gilt:
.
Dem Induktionsbeweis stellen wir zunächst eine Abschätzung voran, die während der Induktion benötigt wird:
Für und erhält man aus die Ungleichung:
.
(+)
Nun zur Induktion selbst:
1. Wir weisen die Differenzierbarkeit von f in jedem nach und unterscheiden dazu drei Fälle:
- : Hier ist f lokal identisch mit 0, also differenzierbar mit Ableitung 0.
-
: Hier ist f lokal identisch mit , also differenzierbar nach Kettenregel. Mit ist:
.
-
: Hier muß die Differenzenquotientenfunktion berechnet werden. Aus
erhält man mittels (+) die Abschätzung . Folgt: . Also ist; f in 0 differenzierbar mit .
2. Sei jetzt f bereits n-mal differenzierbar und wie angegeben zu berechnen. Um nun die
Differenzierbarkeit von sicherzustellen, sind wieder die drei charakteristischen Fälle zu
unterscheiden:
-
: ist hier wieder lokal identisch mit 0, also differenzierbar mit Ableitung 0.
-
: Hier ist lokal identisch mit , also differenzierbar nach Produkt- und Kettenregel. Die Ableitung errechnet man mit geeignet gewählten Konstanten zu:
-
: Auch hier folgt aus
mit (+) die Abschätzung , und damit: .
Mit Hilfe dieser -Funktion f lassen sich nun leicht Beispiele von Testfunktionen herstellen.
| Beispiel: Für jedes ist die Funktion gegeben durch
eine Testfunktion mit .
Beweis: Nach Kettenregel ist eine -Funktion.
Ihr Träger ist eine Teilmenge von , denn ist , so ist , also: .
|
Oft setzt man eine normierte Form der gerade konstruierten Testfunktion ein. Weil nämlich für alle ,
ist . Die Funktion ist somit eine Testfunktion mit der besonderen Eigenschaft .
Die folgenden Skizzen zeigen die Funktionen und .
g1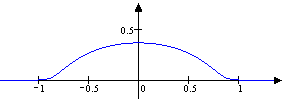 |
g1 0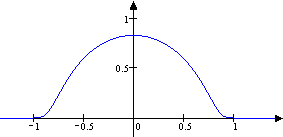 |
Ein weiteres Beispiel dokumentiert die hohe Flexibilität der Testfunktionen.
Überdies sind die hier eingeführten Hut-Funktionen ein unentbehrliches
Hilfsmittel bei der Entwicklung allgemeiner Integrale. Wir notieren zwei Varianten.
Beispiel: (Satz vom -Hut)
- Ist , so gibt es eine Testfunktion mit
- für alle
- für
- für .
- Zu jedem abgeschlossenen Intervall und jedem gibt es eine Testfunktion mit
-
für alle
-
für
-
für
Jede Funktion dieser Art nennen wir einen -Hut für .
|
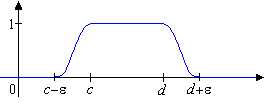 |
Beweis:
Zu 1.: Wir setzen wieder die oben eingeführte -Funktion
f ein.
Für ist , für ist . Da stets , hat man für alle x:
.
Die Funktion
ist daher eine -Funktion
auf ganz . Sie besitzt offensichtlich
die drei angegebenen Eigenschaften.Zu 2.: Wir gewinnen einen -Hut für durch eine
geeignete Verschiebung der gerade konstruierten Funktion h:
Setzt man in 1. und , so leistet die -Funktion
das Gewünschte:
Ist , so ist , d.h. .
Liegt x außerhalb , so ist , also ist .
|
Beliebige Funktionen nehmen definitionsgemäß außerhalb ihres Träger nur
den Wert 0 an. Bei einer -Funktion g gilt dieses Verhalten in geeigneten Bereichen sogar für alle
Ableitungen ! Die folgende Bemerkung führt dies
präzise aus:
Bemerkung: Es sei und ein Intervall, das den Träger von g
umfasst, also . Dann gilt für alle :
- für alle .
für alle .
- .
.
Beweis:
Zu 1.: In jedem Punkt bzw. ist g lokal identisch
mit 0, stimmt hier also mit dem Ableitungsverhalten der Nullfunktion
überein. Zu 2.: Als differenzierbare Funktion ist in a stetig. Mit für alle ist somit auch: .
Auf ähnliche Weise ergibt sich: .
|
Die folgende Definition vermischt nun Inhalte der Analysis mit algebraischen
Aspekten.
| Definition und Bemerkung: ist ein Untervektorraum von .
Den zugehörigen Dualraum, also den Vektorraum der Linearformen auf bezeichnen wir mit dem Symbol
Die Elemente von D nennen wir verallgemeinerte
Funktionen oder Distributionen.
Beweis: Wir weisen für die drei kennzeichnenden Eigenschaften eines Unterraums nach:
-
und .
-
Sind so sind dies zwei -Funktionen, deren Träger jeweils in einem Intervall liegen, etwa bzw. . Dann ist auch eine -Funktion.
Für ihren Träger gilt:
.
-
Ist mit und , so ist eine -Funktion deren Träger leer ist (falls ) oder gleich ist (falls ). In jedem Fall
also hat man: .
|
Beispiel: Die Diracsche Deltaform ist nach einem Beispiel in 9.10 eine Distribution.
|
Das nächste Beispiel stellt eine ganze Gruppe von Distributionen vor. Der Ausdruck verallgemeinerte
Funktion hat hier seinen Ursprung.
Definition und Beispiel: Ist eine stetige Funktion, so ist durch die Festsetzung
mit .
eine Distribution gegeben.
Distributionen dieser Form nennen wir regulär.Beweis: Als
stetige Funktion ist integrierbar. Wir zeigen zunächst:
Das Integral hängt von Wahl des Intervalls nicht ab, ist also wohldefiniert. Sei dazu ein weiteres Intervall mit .
Setzt man und , so ist
.
Auf den (möglicherweise einpunktigen) Teilintervallen und ist , man hat also:
.
Dieselbe Überlegung für das Intervall führt zu
.
Nun zur Linearität:
Sind mit bzw. , so gilt mit und :
.
Und da, wie gerade
gezeigt, das Integral nicht von der Wahl des Intervalls abhängt, kann
man zur Berechnung das Intervall heranziehen:
.
|
Beispiel:
-
Jede konstante Funktion ist stetig, die zugehörige Distribution also regulär.
Dabei gilt offensichtlich: .
-
ist nicht regulär.
Beweis:
Zu a.: Für mit hat man:
.
Zu b.: Angenommen, es gibt eine stetige Funktion f, so dass . Da f auf jedem abgeschlossenen Intervall beschränkt ist, findet man ein , so dass
.
Sei nun h ein -Hut für . Die folgende Abschätzung liefert den
gewünschten Widerspruch:
.
|
Die regulären Distributionen sind durch "ihr" f eindeutig bestimmt.
Bemerkung: Für zwei stetige Funktionen gilt:
.
Beweis: Sei beliebig. Es reicht nun, eine Folge in zu finden, so dass für jede stetige Funktion gilt: . Dann nämlich kann man
folgendermaßen argumentieren:
.
Zur Konstruktion einer solchen Folge setzen wir
die normierten Testfunktionen aus dem ersten Beispiel ein. Da Integrale verschiebungsunabhängig sind, ist
auch die Funktion
eine
normierte Testfunktion: .
Sei nun
und
(beachte: stetige Funktionen
nehmen auf abgeschlossenen Intervallen Maximum und Minimum an!). Da positiv ist, erhält man aus der Monotonie des Integrals die folgende
Abschätzung:
.
D.h. also: . Nach Zwischenwertsatz gibt es daher ein zwischen und , so dass
.
Da nun offensichtlich , folgt schließlich aus der
Stetigkeit von f:
.
|
Reguläre Distributionen entstehen aus einer Funktion per Integration. Unser
Integral, das Stammfunktionen-Integral, ermöglicht es, diesen Vorgang für jede
stetige Funktion durchführen. Mit einem leistungsstärkeren Integralbegriff
ließe sich allerdings eine größere Gruppe von Funktionen, die sog. lokal-integrierbaren
Funktionen, zur Bildung
regulärer Distributionen heranziehen.
Die nachfolgenden Konstruktionen haben zum Ziel, wenigstens den Indikatorfunktionen von
Intervallen reguläre Distributionen zuzuordnen. Dabei werden wir zwischen einem
offenen und einem abgeschlossenen Intervall keinen Unterschied machen. Die
Bezeichnung stehe daher im Weiteren für irgendein Intervall, wie etwa .
Definition: Für ein festes setzen wir zur Abkürzung . Durch die Festsetzung
, mit
ist eine Distribution gegeben.
Beweis:
Wir gehen wie bei der Einführung der Distribution vor. Wie dort zeigen wir zunächst: Das Integral hängt nicht von der Wahl des
Intervalls ab. Sei dazu ein weiteres Intervall, das den Träger von g umfasst. O.E. sei etwa und damit auch . Folgt:
, denn für alle .
Zur Linearität: Sei mit bzw. .
Mit und hat man
wieder
,
so dass man bei der Integration das Intervall einsetzen darf:
.
|
Analog führt man für ein festes die Distribution ein. Für ein beliebiges Intervall setzen wir:
.
Beispiel:
-
-
|
Wir verallgemeinern nun den Ableitungsbegriff. Die Regel der partiellen
Integration liefert dabei einen entscheidenden Hinweis:
Für eine stetig differenzierbare Funktion f und eine
Testfunktion mit hat man nämlich:
(beachte:
!).
Die Werte, die die reguläre Distribution auf den Testfunktionen annimmt, lassen sich also bis auf das Vorzeichen ersetzen,
durch die Werte, die auf den
Ableitungen der Testfunktionen annimmt! Dieses Verhalten liegt der folgenden
Definition zu Grunde:
Definition: Für und setzen wir
.
heißt die n-te Ableitung
von L. Wie üblich schreiben wir statt und setzen zusätzlich .
|
| Bemerkung: . Beweis: Zunächst beachte man, dass mit g auch , ist also wohldefiniert. Es bleibt also nur
noch die Linearität von nachzuweisen:
|
Die Distributionenableitung setzt in geeigneter Weise die klassische Ableitung fort, es handelt
sich also um einen verallgemeinerten Ableitungsbegriff:
| Bemerkung: Für gilt:
.
Beweis: Sei mit .
Zunächst gilt nach einer Bemerkung zuvor: für alle . Die partielle Integration kann also ohne
Berücksichtigung der Randwerte ausgeführt werden:
.
|
Im Distributionensinn können jetzt aber auch Funktionen abgeleitet werden,
die im klassischen Sinn nicht differenzierbar sind! Wir zeigen dies am Beispiel
der Betrags- und der Heavisidefunktion.
Beispiel:
-
.
-
.
Beweis: Sei mit . Für und gilt
zunächst: , und damit:
und
|
Von den klassischen Ableitungsregeln lassen sich die Summen- und die
Faktorregel bequem übertragen. Die anderen Regeln stehen überhaupt nicht zur
Diskussion, denn für Distributionen sind weitere Rechenarten nicht definiert.
Bemerkung: Für gilt:
-
.
-
.
-
.
Beweis: Sei beliebig.
Zu 1.: . 2. zeigt man analog.
Zu 3.: .
|